
Two brief notes on the latent variable formulation of binary response models and the use of alternative links. First we plot three different links in a standardized scale. Second we compare logit and probit estimates for a model of contraceptive use.
Let us reproduce Figure 3.7, which shows the logit, probit and complementary log-log link, after standardizing the latent variable so it has mean 0 and variance 1. The probit link is based on the standard normal distribution, which is already standardized. The logit link is based on the standard logistic distribution, which has mean 0 and variance π2/3. The c-log-log link is based on the extreme value (log Weibull) distribution, with mean 0.577 and variance π2/6.
> library(ggplot2)
> library(tidyr)
> z = seq(-2, 2, .05)
> links <- data.frame(z, probit = pnorm(z), logit = plogis(z*pi/sqrt(3)),
+ cloglog = 1-exp(-exp(-0.577 + z * pi/sqrt(6))))
> links.longer <- pivot_longer(links, cols=c("probit", "logit","cloglog"),
+ names_to="link")
> png(filename="fig37r.png", width=500, height=400)
> ggplot(links.longer, aes(z, value, linetype=link)) + geom_line() +
+ scale_linetype_manual(
+ values=c("probit"="solid", "logit"="dashed", "cloglog"="longdash")) +
+ ggtitle("Figure 3.7. Probit, Logit and C-log-Log Links",
+ subtitle="Standardized") + ylab("Probability") + xlab("Linear Predictor")
> dev.off()png
2 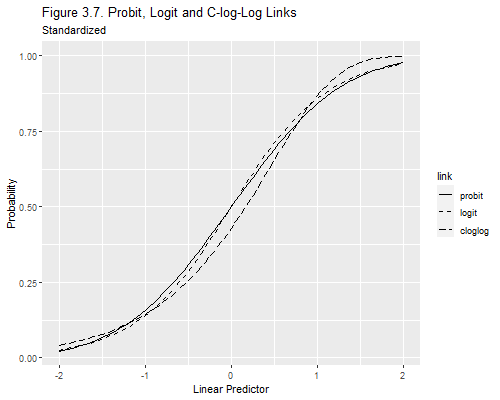
As you can see, the logit and probit links are virtually indistinguisable. The c-log-log link looks different, but one would still need very large sample sizes to be able to distinguish it from the others.
We will fit a probit model to the data on contraceptive use by age and desire for more children. Following the notes we will pick the specification where age is treated linearly and we include an interaction between age and desire for no more children. To simplify interpretation of the interaction we center age at 30 years.
> library(haven)
> library(dplyr)
> cuse <- read_dta("d:/dataweb/wws509/datasets/cusew.dta")
> cuse <- mutate(cuse, agemc = c(-10,-2.5,5,15)[age], Y = cbind(users, nonusers))
> probit <- glm(Y ~ agemc*nomore, family=binomial(link="probit"), data=cuse)
> probit
Call: glm(formula = Y ~ agemc * nomore, family = binomial(link = "probit"),
data = cuse)
Coefficients:
(Intercept) agemc nomore agemc:nomore
-0.73741 0.01287 0.43898 0.03048
Degrees of Freedom: 15 Total (i.e. Null); 12 Residual
Null Deviance: 165.8
Residual Deviance: 29.01 AIC: 108.5Probit coefficients can be interpreted in terms of a standardized latent variable representing a propensity to use contraception, or the difference in expected utilities between using and not using contraception.
We see that the propensity among women who want more children increases with age at the rate of just over one tenth of a standard deviation per year. More interestingly, the propensity is 0.44 standard deviations higher among women who want no more children than among those who want more at age 30. This difference increases by 0.03 standard deviations per year of age, so it is 0.13 standard deviations at age 20 but 0.74 standard deviations at age 40. As a result, the propensity to use contraception among women who want no more children is 0.04 standard deviations higher per year of age.
It may be of interest to compare logit and probit coefficients. One way to compare them is to divide the logit coefficients by π/√3 = 1.8. This standardizes the logistic latent variable to have variance one, so the coefficients have the same interpretation as a probit model. The first two columns in the table below show that the two sets of coefficients are in fact very similar
> logit <- glm(Y ~ agemc*nomore, family=binomial, data=cuse)
> data.frame(probit=coef(probit), std.logit=coef(logit)/(pi/sqrt(3)),
+ amemiya=coef(logit)/1.6) probit std.logit amemiya
(Intercept) -0.73740780 -0.66570995 -0.75466518
agemc 0.01286865 0.01203162 0.01363934
nomore 0.43897588 0.40176119 0.45544636
agemc:nomore 0.03048069 0.02645902 0.02999459Gelman and Hill (2007), following Amemiya (1981), recommend dividing by 1.6. This factor was chosen by trial and error to make the transformed logistic approximate the standard normal distribution over a wide domain. As shown in the third column above, it gives a somewhat closer approximation to the probit coefficients in our example, particularly for the interaction term. Of course the difference between dividing by 1.8 or 1.6 is not going to be large.
Gelman, A. and Hill, J. (2007) Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge: Cambridge University Press.
Amemiya, T. (1981). Qualitative response models: a survey. Journal of Economic Literature, 19:1483–1536.
Updated fall 2022